画像に対してAIを使って何が映っているのかを判断させる。
SSD KERASというオープンソースのソフトウェアを使う。
VirtualBoxを使ってUbuntu16.04LTSをインストール。
まっさらな環境から主に下記URLの通りの手順を踏んでインストール。
pip3のインストール & アップグレード
sudo apt-get install python3-pip python3-dev
pip3 install --upgrade pipTensorFlowのインストール
$ pip3 install tensorflow==1.1.0KERASのインストール
$ sudo pip3 install keras==1.2.2matplotlibのインストール
$ pip3 install matplotlibopencvのインストールに必要なパッケージを取得
$ sudo apt-get install --assume-yes build-essential cmake git
$ sudo apt-get install --assume-yes build-essential pkg-config unzip ffmpeg qtbase5-dev python-dev python3-dev python-numpy python3-numpy
$ sudo apt-get install --assume-yes libopencv-dev libgtk-3-dev libdc1394-22 libdc1394-22-dev libjpeg-dev libpng12-dev libtiff5-dev libjasper-dev
$ sudo apt-get install --assume-yes libavcodec-dev libavformat-dev libswscale-dev libxine2-dev libgstreamer0.10-dev libgstreamer-plugins-base0.10-dev
$ sudo apt-get install --assume-yes libv4l-dev libtbb-dev libfaac-dev libmp3lame-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev
$ sudo apt-get install --assume-yes libvorbis-dev libxvidcore-dev v4l-utilsopencvのコードを取得
$ git clone https://github.com/opencv/opencv.git
$ cd opencvopencvのビルド。この作業、私の環境では2時間くらいかかった。
$ mkdir build
$ cd build/
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D WITH_TBB=ON -D WITH_V4L=ON -D WITH_QT=ON -D WITH_OPENGL=ON -D WITH_CUBLAS=ON -DCUDA_NVCC_FLAGS="-D_FORCE_INLINES" ..
$ make -j $(($(nproc) + 1))
opencvのインストール
$ sudo make install
$ sudo /bin/bash -c 'echo "/usr/local/lib" > /etc/ld.so.conf.d/opencv.conf'
$ sudo ldconfig
$ sudo apt-get updatessd_kerasのダウンロード
$ git clone https://github.com/rykov8/ssd_keras.git
$ cd ssd_keras学習モデルのダウンロード
下記サイトより
rykov8/ssd_keras: Port of Single Shot MultiBox Detector to Keras
このhereから
このファイルをダウンロードする。
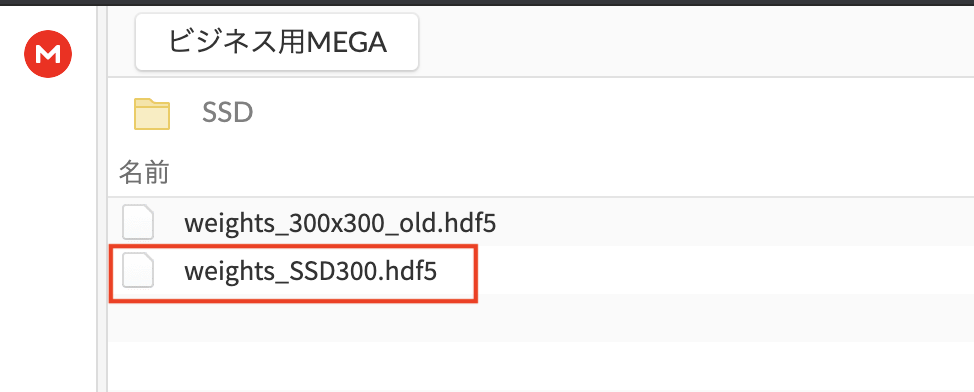
ダウンロードした学習モデルは、ssd_kerasのディレクトリの中に配置。
この時、ssd_kerasのディレクトリは下記の通りの構成になっている。
LICENSE
PASCAL_VOC
README.md
SSD.ipynb
SSD_training.ipynb
__pycache__
gt_pascal.pkl
main.py
pics
prior_boxes_ssd300.pkl
ssd.py
ssd_layers.py
ssd_training.py
ssd_utils.py
testing_utils
weights_SSD300.hdf5
ここからjupyter notebookをインストールすると参考のサイトには書いてあったが、自分の環境ではjupyterを使ったコードの実行はできなかった。
なので、jupyterに使われていたコードを編集して、一つのプログラムにして実行した。
その際使ったプログラムは下記のとおり
main.py
from keras.applications.imagenet_utils import preprocess_input
from keras.backend.tensorflow_backend import set_session
from keras.preprocessing import image
import matplotlib.pyplot as plt
import numpy as np
from scipy.misc import imread
import tensorflow as tf
from ssd import SSD300
from ssd_utils import BBoxUtility
import glob
picture_dir = './pics'
def make_file_list()-> []:
result = []
files = glob.glob('{}/**'.format(picture_dir), recursive=True)
for f in files:
if f[-3:] == 'jpg':
result.append(f)
return result
def extract_file_name(path:str)-> str:
idx = path.rfind('/')
name = path[idx + 1:]
idx = name.rfind('.')
result = name[:idx]
return result
def extract_file_path(path:str)-> str:
result = path.split('/')[-2]
# filename = path.split('/')[-1]
# result = '{}/{}'.format(dir, filename)
return result
#matplotlib inline
plt.rcParams['figure.figsize'] = (8, 8)
plt.rcParams['image.interpolation'] = 'nearest'
np.set_printoptions(suppress=True)
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.45
set_session(tf.Session(config=config))
voc_classes = ['Aeroplane', 'Bicycle', 'Bird', 'Boat', 'Bottle',
'Bus', 'Car', 'Cat', 'Chair', 'Cow', 'Diningtable',
'Dog', 'Horse','Motorbike', 'Person', 'Pottedplant',
'Sheep', 'Sofa', 'Train', 'Tvmonitor']
# voc_classes = ['Bird', 'Bus', 'Car', 'Cat','Cow', 'Dog', 'Motorbike', 'Person', 'Sheep']
NUM_CLASSES = len(voc_classes) + 1
input_shape=(300, 300, 3)
model = SSD300(input_shape, num_classes=NUM_CLASSES)
model.load_weights('weights_SSD300.hdf5', by_name=True)
bbox_util = BBoxUtility(NUM_CLASSES)
# files = glob.glob('./pics/dataset/**', recursive=True)
inputs = []
images = []
files = make_file_list()
for f in files:
# filenames.append(extract_file_name(f))
img_path = f
img = image.load_img(img_path, target_size=(300, 300))
img = image.img_to_array(img)
images.append(imread(img_path))
inputs.append(img.copy())
inputs = preprocess_input(np.array(inputs))
preds = model.predict(inputs, batch_size=1, verbose=1)
results = bbox_util.detection_out(preds)
#%%time
a = model.predict(inputs, batch_size=1)
b = bbox_util.detection_out(preds)
idx = 0
for i, img in enumerate(images):
# Parse the outputs.
det_label = results[i][:, 0]
det_conf = results[i][:, 1]
det_xmin = results[i][:, 2]
det_ymin = results[i][:, 3]
det_xmax = results[i][:, 4]
det_ymax = results[i][:, 5]
# Get detections with confidence higher than 0.6.
top_indices = [i for i, conf in enumerate(det_conf) if conf >= 0.6]
top_conf = det_conf[top_indices]
top_label_indices = det_label[top_indices].tolist()
top_xmin = det_xmin[top_indices]
top_ymin = det_ymin[top_indices]
top_xmax = det_xmax[top_indices]
top_ymax = det_ymax[top_indices]
colors = plt.cm.hsv(np.linspace(0, 1, 21)).tolist()
plt.imshow(img / 255.)
currentAxis = plt.gca()
# f = open('{}/{}/labels.txt'.format(picture_dir, extract_file_path(files[idx])), mode='a')
for i in range(top_conf.shape[0]):
xmin = int(round(top_xmin[i] * img.shape[1]))
ymin = int(round(top_ymin[i] * img.shape[0]))
xmax = int(round(top_xmax[i] * img.shape[1]))
ymax = int(round(top_ymax[i] * img.shape[0]))
score = top_conf[i]
label = int(top_label_indices[i])
label_name = voc_classes[label - 1]
display_txt = '{:0.2f}, {}'.format(score, label_name)
coords = (xmin, ymin), xmax-xmin+1, ymax-ymin+1
color = colors[label]
currentAxis.add_patch(plt.Rectangle(*coords, fill=False, edgecolor=color, linewidth=2))
currentAxis.text(xmin, ymin, display_txt, bbox={'facecolor':color, 'alpha':0.5})
# f.write('{} -> {} : {:0.2f}\n'.format(extract_file_name(files[idx]), str(label_name), score))
# f.close()
plt.show()
idx += 1
なお、このプログラムを実行すると、python3-tkが足りないと言われるのでこれをインストール
sudo apt install python3-tkさらに、cannot import name ‘imread’というエラー
これは、scipyのバージョンが違う場合に発生するらしい。
ついてはscipyのバージョンを指定してインストール
pip3 install scipy==1.1.0h5pyが足りないと言われる場合もある。
pip3 install h5pyこれにて動作確認。
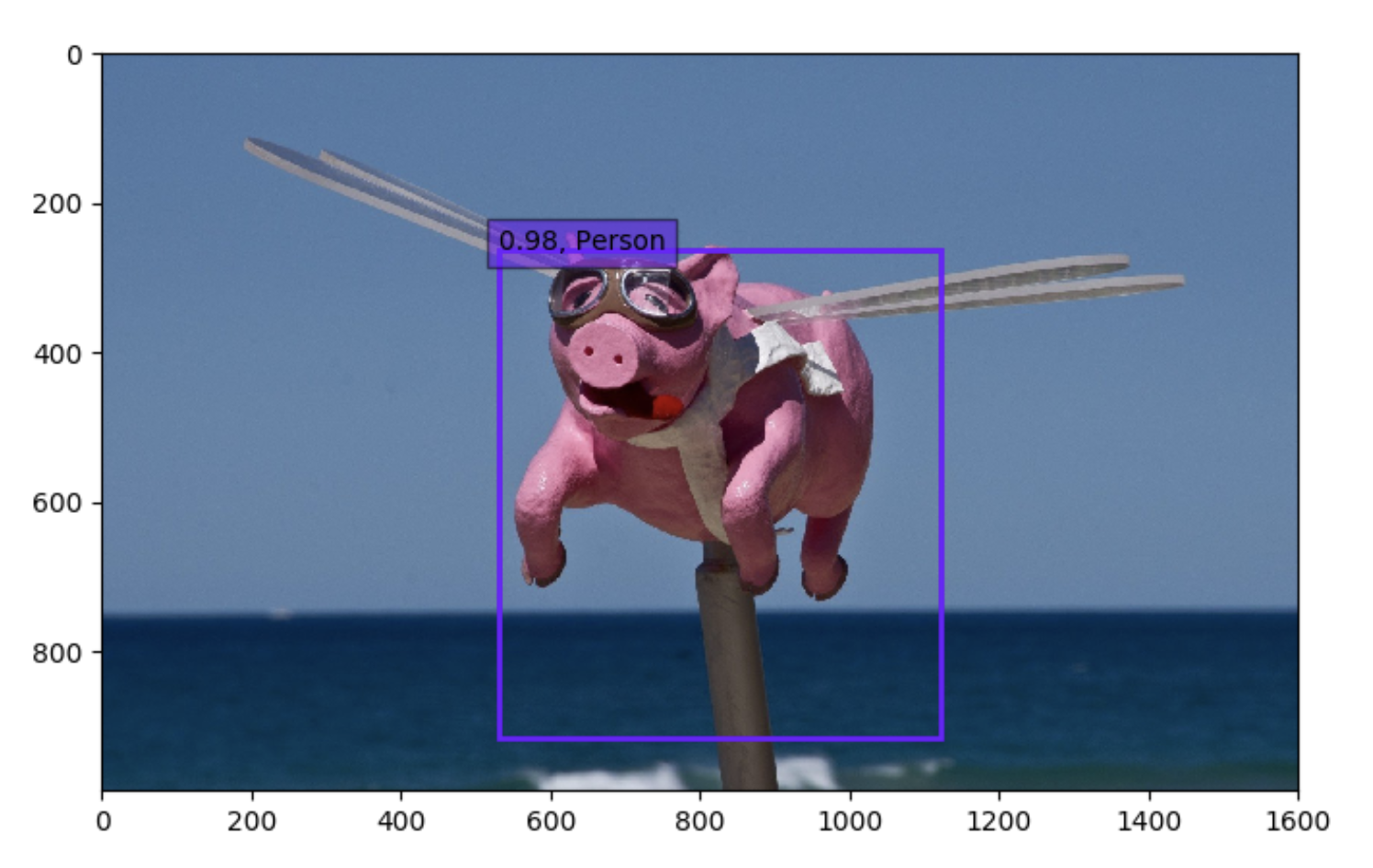
人間は結構取れる。

でもちょっと意地悪するとこんな感じ。
上記の工程は主に下記のサイト様を参考にしてやらせていただきました。
本当に助かりました。感謝致します。
